
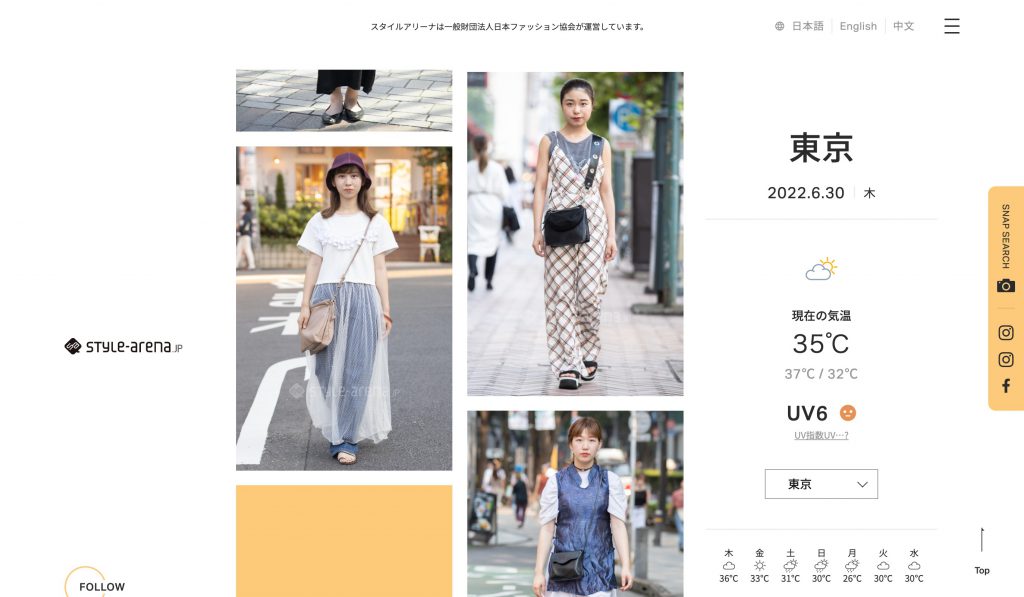
東京では渋谷や銀座など様々な街が栄え、エリアごとにファッション文化が異なっているイメージは皆さんお持ちではないでしょうか。
今回は東京のストリートファッションを2002年から発信している『スタイルアリーナ』提供の10年分の膨大なストリートスナップをAIで画像解析にかけることで、エリアごとの特徴をあらためて検証しました。
果たして結果は皆さんの頭の中のイメージとどれほど一致するものでしょうか?
Contents
1万枚を超える10年分のストリートスナップ – データ概要と分析手法
分析には2009年から2018年の間にかけて『スタイルアリーナ』に掲載されたストリートスナップを用いました。渋谷・原宿・表参道・代官山・銀座の5エリアごとに、約2,200〜2,500枚を対象としています。
- 場所
- 原宿
- 渋谷
- 表参道
- 代官山
- 銀座
- データ数
- 2,482
- 2,485
- 2,197
- 2,197
- 2,197
これらのスナップを、ニューロープが独自開発している画像認識技術で解析。スナップに含まれるアイテムのカテゴリー・色・素材・シルエットなどをタグ付けしました。
また各スナップの被写体が好むブランドもアンケート形式で収集されています。
これらテキスト情報を、自然言語処理の手法である “TF-IDF法” を用いてエリア別のファッションの特徴を分析しました。
TF-IDFは、TF (term frequency: 出現頻度) に対して、IDF (inversed document frequency: 文章頻度の逆数)を乗算することで、文章内における単語の重要度を計算する手法です。
今回のケースでは「一つの地域=テキスト」とみなし、画像から得られたタグやアンケートから得られた「好きなブランド」をワードとしてみなします。
「ある地域(テキストd)に頻出するタグ(ワードt)はその地域の特徴を表している」という前提の元、タグの出現頻度をTFとして計算します。
また地域に関わらず頻出するベーシックなタグ(ブラック、シャツ、スニーカーなど)が重みを持ってしまう問題を回避するために、IDFをかけます。
IDFは「すべての地域」を「該当タグが1つ以上出現した地域の数」で割った数からなります(正確には分母が0にならないように分母に1を足すなどの調整をしています)。従って多くの地域で出現したタグはIDFの値が小さくなります。
原宿ではローカット、代官山ではグレーのトップス、銀座ではハンドバッグがそれぞれ特徴に
それぞれの地域について、上位のアイテムを見てみましょう。(前述の手法に基づく)
- 原宿:パンツ・黒の靴・スニーカー・長袖・白のトップス
- 渋谷:黒の靴・パンツ・長袖・黒のトップス・白のトップス
- 表参道:パンツ・黒の靴・黒のトップス・長袖・黒のパンツ
- 代官山:パンツ・黒の靴・長袖・スニーカー・黒のトップス
- 銀座:黒の靴・パンツ・ショルダーバッグ・ハンドバッグ・チェーン付きバッグ
銀座に関しては上位3種類のバッグが銀座のイメージと一致するのではないでしょうか。
ただし、地域が5つと限られているため、IDFの効果が小さく、基本的にはどの地域も同じようなアイテムが並んでいます。
この問題を回避するために、出現頻度の高いタグを対象から除外します。今回は全体で3,000回以上出現するタグを取り除きました。長袖・黒い靴・パンツ・黒のトップス・ニット・ジャケットなどが該当します。
この条件で再びTF-IDFを計算すると、以下のような結果となります。
- 原宿:十分丈のボトムス・スカート・ベスト・白い靴・ローカットシューズ
- 渋谷:ブーツ・チェーンバッグ・サンダル・スカート・ショートブーツ
- 表参道:十分丈のボトムス・ベスト・スキニー・コート・黒のバッグ
- 代官山:十分丈のボトムス・ベスト・グレーのトップス・コート・ストレートのボトムス
- 銀座:ハンドバッグ・チェーンバッグ・スカート・パンプス・ブーツ
カジュアルな印象のある原宿ではローカットシューズや白い靴といったタグが目立ちます。13年前のスナップも含まれていることを考えると、スタンスミスの流行なども影響していることでしょう。
一方、コンサバティブな印象の銀座ではハンドバッグやチェーンバッグ、パンプスといったタグが上位を占めます。
銀座と原宿では服のテイストが大きく異なることは上位タグからも予測ができますが、どれだけ異なるものなのかを実際に数値で表す指標として、 “cos類似度” が有用です。
cos類似度では地域ごとに「タグの種類だけ次元があるベクトル」とみなし、地域と地域を比較した際にベクトルとベクトルの角度の大きさを求めます。角度が小さい方がベクトル同士の類似度が高いことを意味します。角度が0の時にcosは1の値を取るので、最終的には計算された数値が大きいほど類似度が高いと考えられます。
ファッションスタイルの「距離」が最も遠いのは原宿と銀座
高頻度で現れるタグを除いたTF-IDFの値を用いて、それぞれの地域のcos類似度を計算しました。
- 場所
- 原宿
- 渋谷
- 表参道
- 代官山
- 銀座
- 原宿
- 1
- 0.93
- 0.94
- 0.95
- 0.90
- 渋谷
- 0.93
- 1
- 0.94
- 0.92
- 0.93
- 表参道
- 0.94
- 0.94
- 1
- 0.95
- 0.93
- 代官山
- 0.95
- 0.93
- 0.95
- 1
- 0.92
- 銀座
- 0.90
- 0.94
- 0.93
- 0.91
- 1
最も類似度が低いのは原宿と銀座という結果になりました。
一方で原宿と表参道や代官山、渋谷と表参道などは類似度の高さがうかがえます。
「好きなブランド」は原宿と代官山、表参道と代官山などが類似
続いて、被写体の「好きなブランド」に基づいて同じくcos類似度の分析をかけました。
- 場所
- 原宿
- 渋谷
- 表参道
- 代官山
- 銀座
- 原宿
- 1
- 0.39
- 0.62
- 0.64
- 0.24
- 渋谷
- 0.39
- 1
- 0.46
- 0.39
- 0.53
- 表参道
- 0.62
- 0.46
- 1
- 0.65
- 0.38
- 代官山
- 0.64
- 0.39
- 0.65
- 1
- 0.31
- 銀座
- 0.24
- 0.53
- 0.37
- 0.31
- 1
原宿、表参道、代官山には類似性が認められます。
隣接しているにも関わらず、原宿と渋谷の類似性は低いという結果に。
5つの地域の中でも、渋谷と銀座は独特の好みを持っていることが明らかになりました。
今回は様々な手法を組み合わせて地域の特性や地域間の類似度などを分析しました。
「意外」と思われるものもあれば、イメージ通りのものもあったのではないでしょうか。
意外性を発見することにはもちろん、「想定通り」の結果についても、例えば表参道と代官山がどれくらい似ているのか、0.6なのか0.65なのか、定量化することに意義があります。
経験や感覚に頼らざるをえなかった業界に、私たちニューロープはAIやデータサイエンスなどの手法を持ち込むことで意思決定やコミュニケーションをスムーズにし、業界全体を次のステージに推し進めていくことを目指しています。
次回は10年分のスナップの「時系列」に着目して分析を進めていきます。
分析・レポート: 吉田史明 / 記事編集: 酒井聡
関連リンク
- 東京のストリートファッションを発信する – スタイルアリーナ
- ファッショントレンドを分析する – #CBK forecast
- ファッション特化の画像解析 – #CBK scnnr
#CBK encyclopedia編集チームの公式アカウント。
内部情報、業界情報を発信していきます!